Memory(メモリ)
コンピュータは、CPU、メモリ、外部記憶、周辺機器などからを構成されます。そのうちの一つ、メモリはCPUと共にコンピュータには欠かせない要素です。
現在のPC(パーソナルコンピュータ)には、4Gバイトを超えるメモリを搭載するのが一般的です。しかし、初期のPCでは64Kバイト以下といった、現在では考えられないような少ないメモリしか搭載されていませんでした。プログラマは、その少ないメモリをいかに有効に利用するかを常に考えなければなりませんでした。このため、物理的なメモリについての知識が必須でした。メモリには0からのアドレス(番地)が与えられ、どこに何を置くかを常に意識していました。例えば、最初期のPCのOSであるCP/Mやその派生であるMS-DOSでは、0番地から100H番地はCPUアーキテクチャとCP/Mのワークエリアとして占有され、アプリケーションは100H以降を利用することになっていました。また、ビデオRAMやOSのコードの場所(システム領域)も明示されていて、それらのエリアを避けてメモリを利用することが暗黙の約束でした。どこに何があるかが明らかだったため、OSの一部を書き換えてカスタマイズするといった、現在の常識からは考えられないようなことも行われていました。つまり、すべて自己責任で、PCは完全に『所有者の物』だったのです。
さて、すでにお気づきかと思いますが、アドレスの数値表現では数字の後ろに「H」を付け、16進数であることを表しています。C言語での頭に「0x」を付けることと同じです。
現在でもメモリには一意のアドレスが与えられていますが、OS(Windows,Linuxなど)によって仮想アドレスが利用され、一般的なプログラマは実際のアドレスを知る必要がなくなっています。なお、仮想アドレスについてはここでは特に言及しません。
CPUアーキテクチャによりエンディアン(Endian)という16ビット以上のデータの並びが定義されます。Big-endianとLittie-endianの2種類があります。メモリ内での整数のバイト並びは次の図のようになります。図の左側はCPU内での32ビット値の表現(0xdeadbeaf)、右はメモリ上でのデータの格納順になります。Big-endianでは、メモリ内に上位バイトから順に格納されます。Little-endianではメモリに下位バイトから上位バイトに向かって並べられます。
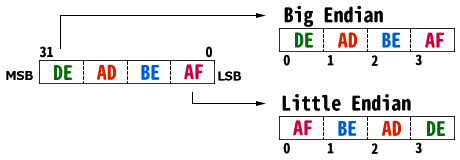
PCで多く利用されているx86系はLittie-endianを採用しています。ARM系ではどちらも利用することができます(CPU命令は除く)。エンディアンについては通常は意識することはありませんが、デバッグ時にメモリの内容を読む場合に注意が必要です。また、ネットワークでのデータ転送時には通常Big-endianが使用されるため、Littie-endianのシステムでは変換が必要になることがあります。
メモリは一般的に8ビット・バイトを構成単位として、アドレスの低い方(小さい方)から順に利用されていきます。例えば、16ビット整数(short)は2バイトが必要ですが、メモリの連続した2バイトにエンディアンに従って格納されます。32ビット整数や64ビット整数も同様にして格納されます。バイト列である文字列も低いアドレスから上位アドレスに向かって格納されていきます。
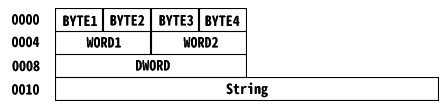
CPUによっては、アラインメントというデータの境界が設定されているものがあります。x86系では通常は問題になりませんが、SSEを利用する場合や、ARMなどではアラインメントを意識する必要があります。アラインメントが必要なCPUでは、16ビット整数はアドレスの2バイト境界(2の倍数、偶数アドレス)、32ビット整数は4バイト境界(4の倍数)、64ビット整数は8バイト境界に配置する必要があります。C/C++を利用する場合、VisualStudioなどでプロジェクトを作成する際に自動的にアラインメントが設定されるため、意識せずにコーディングをするプログラマが殆どでしょう。しかし、この無意識のコーディングによって使用されないメモリがプログラム内にたくさんあるかもしれません。後述するCPUキャッシュを有効利用する上では、意識した方が良い結果を生みます。
Stack(スタック)
通常メモリは低いアドレスから順に使用されると書きましたが、スタックは逆に上位アドレスから順に使用されるデータ構造で、CPUの機能としてサポートされています。最もよく使われる場面は、関数呼び出しにおいて後述するレジスタの退避・復帰です。また、C/C++ではローカル変数の確保もスタック上で行われます。
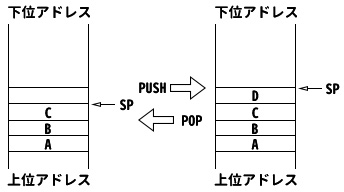
上の図で、簡単な例を挙げましょう。SPはスタックポインタというレジスタです。スタックにはpush(プッシュ)とpop(ポップ)の2つの操作があります。プッシュ操作はSPを新しい記憶用のアドレスに移動させデータを書き込む、ポップ操作はデータを読み込みSPレジスタを増加させるという動きをします。
『新しいアドレスに移動させ』とか『SPレジスタを増加させ』などと、わかりにくい書き方をしましたが、スタックポインタの値をどれだけ加減算するかはCPUのアーキテクチャによるためです。CPUレジスタが16ビットの場合は、通常スタックポインタは2づつ(2バイト分)加減算されます。これはpush/popの主な目的がレジスタを退避・復帰させるためです。32ビットCPUの場合は4づつ(4バイト分)加減算され、現在主流の64ビットCPUでは8づつ(8バイト分)加減算されます。
前述したように、現在ではスタックメモリ領域はレジスタの退避・復帰にのみ使用されるわけではありません。C/C++ではローカル変数がスタック上に置かれます。
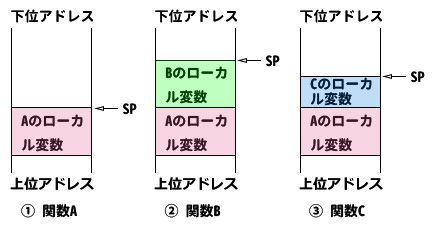
例えば、関数A(上図①)から関数Bを呼び出した場合、関数Bでは自身のローカル変数をスタックに確保します(上図②)。関数Bの処理が終わると関数Aに戻りますが、この時スタックポインタは関数Bの呼び出し以前の状態に戻され、それまで使用していた関数Bのローカル変数はメモリから消えます(上図①)。次に関数Cが呼び出されると、以前関数Bが使用していたスタック領域が関数C用のローカル変数用に再利用されることになります(上図③)。このように、スタックは無限に使いまわせるメモリとして使用されます。もちろん無限というのは言い過ぎで、関数呼び出しが重なれば重なるほどスタック領域は圧迫されていき、最後には足りなくなることがあります。しかし、通常のプログラミングではスタック領域が足りなくなることはほとんどありません。ただし、ローカル変数に巨大な配列などを確保しようとするとプログラムが動かなくなることはありますので、大きな配列などはmalloc関数やnewで確保し、使い終わったら開放するという方法を取ってください。Microsoftによれば、既定のスタックサイズは1MBです。
Register(レジスタ)
レジスタはCPU内にある高速にアクセスできるメモリです。通常のメモリと異なり、CPUが直接読み書きでき、また演算をレジスタの内容に対して行います。
最近のCPUはパイプライン化されており、CPUの演算はパイプライン上で行われます。CPUはレジスタの内容をパイプラインに乗せ、演算を施したのち、結果はレジスタに戻されます。メモリ上のデータは、パイプライン経由でレジスタに読み込まれ、上記のような処理が行われます。演算結果はメモリに書き出されたり、別の演算に使われたりします。
Intelのi8080では、A、B、C、D、E、H、Lの7つの8ビット汎用レジスタ、SP、PCの16ビット固定機能レジスタ、そしてF(フラグジスタ)という構成でした。
ほとんどの演算処理はAレジスタのみで行われていました。SPは既に出てきたスタックポインタで、スタック領域の先頭を指し示すレジスタです。PCはプログラムカウンタと呼ばれ、次に実行するCPU命令を指し示すポインタです。PCは直接変更することはできず、サブルーチンコールやジャンプ命令、またリターン(サブルーチンからの戻り)命令などで変更されます。
Aレジスタ以外の8ビットレジスタは、2つを組合わせてBC、DE、HLという3つの16ビットレジスタとして使用することができました。
Aレジスタで行うことのできる演算は、加算、減算、比較、ビットごとの論理演算、左右ローテートなどです。Aレジスタはアキュムレータと呼ばれ、演算装置と一体化されていました。現在ではパイプライン化されているため、どのレジスタに対しても同じような演算を施すことができるようになっています。
x64(AMD64)には、rax, rbx, rcx, rdx, rsi, rdi, rbp, rsp, r8, r9, r10, r11,r12, r13, r14, r15, rflags, rip の18の64ビットレジスタがあります。rsp、rip、rflagsを除いて汎用的に使用することができます。また、16個の128ビットSSEレジスタ、xmm0~xmm15があり浮動小数点演算に使用されます。
ARMv8ではr0~r30までの汎用レジスタとSP、PCの32個の64ビットレジスタがあります。また、浮動小数点演算のための32個の128ビット浮動小数点レジスタがあります。128ビット浮動小数点レジスタは、32ビット×4、64ビット×2と単精度4、倍精度2のSIMDレジスタとして機能します。
C/C++では次のようにregisterという修飾子をローカル変数の型の前に付けることができます。
register int c;
ローカル変数を直接CPUレジスタに割り当てることができたのです。しかし、現在のコンパイラでは無視されます。C++17では、使用することもできなくなりました。
現在のC/C++でのレジスタの重要な役割は、関数呼び出しにおける引数がCPUレジスタに割り当てられることです。CPUアーキテクチャやコンパイラにより、いくつの引数がレジスタに割り当てられるかは変わります。この決まりを呼出規約(Calling convention)といいます。
Visual Studio VC++のx64の場合、4つ引数がレジスタに割り当てられます。整数型、ポインタ型の引数は左から順に、rcx, rdx, r8, r9に割り当てられます。浮動小数点型(単精度、倍精度)の引数は左から順に、xmm0、xmm1、xmm2、xmm3に格納され呼び出し先に渡されます。レジスタに割り当てられなかった引数はスタックにプッシュされ呼び出し先関数に渡されます。
次の例は、マイクロソフト社の「x64 calling convention」ページに掲載されている例を引用したものです。
func1(int a, int b, int c, int d, int e, int f); // a in RCX, b in RDX, c in R8, d in R9, f then e pushed on stack func2(float a, double b, float c, double d, float e, float f); // a in XMM0, b in XMM1, c in XMM2, d in XMM3, f then e pushed on stack func3(int a, double b, int c, float d, int e, float f); // a in RCX, b in XMM1, c in R8, d in XMM3, f then e pushed on stack func4(__m64 a, __m128 b, struct c, float d, __m128 e, __m128 f); // a in RCX, ptr to b in RDX, ptr to c in R8, d in XMM3, // ptr to f pushed on stack, then ptr to e pushed on stack
Cache(キャッシュ)
キャッシュメモリはCPU内に設置された高速、小容量のメモリです。キャッシュラインと呼ばれる単位で低速なメインメモリの一部をコピーし、必要に応じて高速にCPU内に取り込むことができます。キャッシュラインのサイズはCPUにより異なりますが、32バイトや64バイトが多いようです。
CPUがキャッシュに存在しないデータを読み込む場合、目的とするデータのアドレスを含むキャッシュラインサイズのデータをキャッシュメモリに読み込みます。キャッシュ内容は、基本的にLRU(Least Recent Used:もっとも最後に使用された)により更新されます。キャッシュに読み込まれたデータは、目的とするデータがCPUにコピーされた後も(キャッシュ内で最も古いデータとなるまで)キャッシュ内に存在し続けます。
キャッシュが最も効果を発揮するのは、キャッシュラインサイズで読み込まれた目的外のデータが高速にアクセスできるようになることです。例を示します。
struct something {
char status;
char flag;
short count;
int data;
};
something a;
キャッシュラインが32バイトと仮定して、上記の構造体の a.flag を読み込むと、その周りの構造体メンバも一緒にメモリからキャッシュにコピーされます。構造体のアラインメントは4バイト境界に配置されます(VC++の場合)。構造体 a のサイズは8バイトですから、構造体 a 全体がキャッシュに読み込まれる可能性は高いです。a.flag が読み込まれた後は、a.status や a.count はすでにキャッシュメモリに読み込まれているでしょうから4クロック程度でCPUレジスタに読み込むことができます。他のメンバも同様です。
キャッシュとメモリからの読み込みスピードは、Anandtech.comのこちらの記事が参考になります。記事によれば、EPYC7742では、L1キャッシュでは4クロックサイクル、L2キャッシュでは13クロックサイクル、L3キャッシュでは34クロックサイクル、DRAMではL1キャッシュの100倍以上、それぞれ読み込みにかかるようです。